
ハーネスエンジニアリングとは
AIエージェントの生産性は「環境」で決まる
AIの生産性は、もはや異次元です。OpenAIでは3人のエンジニアで5ヶ月間、約100万行のコードを構築しました。Stripeでは週1,000件以上のPRがAIによってマージされています。
では皆さんは、彼らと同じモデルやツールを使ったとして、このレベルの生産性を出せますか?
なぜ彼らはこんなにも生産性が高いのでしょうか?
決定的な違いは、AIを取り巻く「環境」の差です。どんなルールを与えるか、どんな情報を見せるか、どんなツールを渡すか、どう検証し、どう修正ループを回すか。つまり、AIエージェントの動作環境そのものが精密に設計されています。
彼らが作っているのは、単なる「賢いプロンプト」ではありません。AIが安定して成果を出すための実行環境です。この環境設計こそが、ハーネスエンジニアリングです。
ハーネスエンジニアリングの定義
ハーネスエンジニアリング とは、「AIエージェントが動作する環境そのものを設計する」行為を指します。
ハーネスエンジニアリングの定義は論者によって異なりますが、いずれも「モデルの外側」に焦点を当てている点で共通しています。
- AIエージェントを制御するためのツールやルールなどの総称
- エージェントがミスを繰り返さないよう教育する仕組み
- 複数のコンテキストウィンドウにまたがるタスクでもAIモデルが効果的に作業するためのフレームワーク
- AIモデルをラップし、ツール実行・コンテキスト管理・安全性の担保などを行う仕組み
ハーネスとは何か
AIエージェントが動作する環境(ルール、動作フロー、学習の仕組みなど環境全体)のことです。
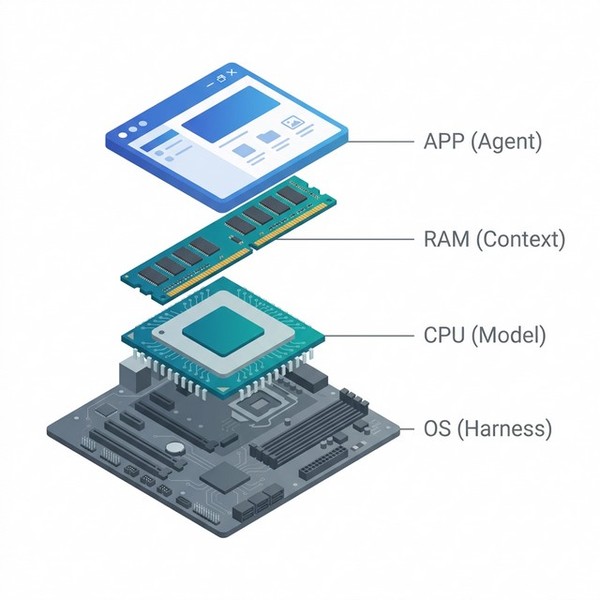
パソコンに置き換えると、さらにわかりやすくなります。
- モデル = CPU
- コンテキストウィンドウ = RAMメモリ
- エージェント = アプリケーション
- ハーネス = OS : アプリが動く環境を提供
LLMがどれだけ賢くても、周辺インフラが不十分ならタスク完了率は低いままです。ハーネスはAIエージェントにとってのOSです。
身近な具体例で理解する
この定義だけだと抽象的に見えるかもしれませんが、実際にはすでに多くの人がハーネスに触れています。
たとえばOpenClawやClaude Codeも、広い意味ではハーネスの一種です。どちらも「モデル単体」を使っているのではなく、モデルの外側にツール、ルール、権限管理、コンテキストの扱い、実行フローなどを組み合わせて、実務で動くエージェント体験に仕立てています。
つまり、私たちが普段「AIコーディングツール」や「コーディングエージェント」と呼んでいるものの多くは、実際にはハーネス込みのシステムです。ハーネスエンジニアリングとは、その外側の仕組みを意図して設計し、改善していくことだと考えるとイメージしやすくなります。
プロンプトからコンテキスト、そしてハーネスへ
プロンプトエンジニアリングの時代
AI駆動開発のエンジニアリングは、以下の順番で進化してきました。
プロンプトエンジニアリング
↓
コンテキストエンジニアリング
↓
ハーネスエンジニアリング最初はプロンプトエンジニアリングでした。AIにどう指示するかが重要だった時代です。
コンテキストエンジニアリングの登場
その次に、AIへ何を見せるかを設計するコンテキストエンジニアリングが重要になりました。
ハーネスエンジニアリングが必要になった理由
そして今、さらに一段進んで、AIエージェントが安定して成果を出せる環境そのものを設計するハーネスエンジニアリングが必須になってきています。
冒頭で触れたように、OpenAIのCodexチームは3人のエンジニアで5ヶ月間に約100万行のコードを構築しました。こうした異次元の成果を出しているチームがやっていることは、単に「優れたモデルを使うこと」ではありません。AIがその力を安定して発揮できるように、ハーネスを設計しているのです。
だから、AI時代のAI駆動開発エンジニアとして成長するなら、学ぶ順番も見えてきます。まずはプロンプトエンジニアリング、次にコンテキストエンジニアリング、そしてその先にあるのがハーネスエンジニアリングです。ここからは、そのハーネスエンジニアリングを実際にどう作り、どう運用していくのかを見ていきます。
ハーネスエンジニアリングの4つの設計領域
ハーネスエンジニアリングは、モデル自体を再訓練して性能を上げる話ではありません。AIエージェントに何を見せ、どう動かし、どう評価し、どう運用するかを設計して、能力を引き出しながら安全性と再現性を担保する取り組みです。
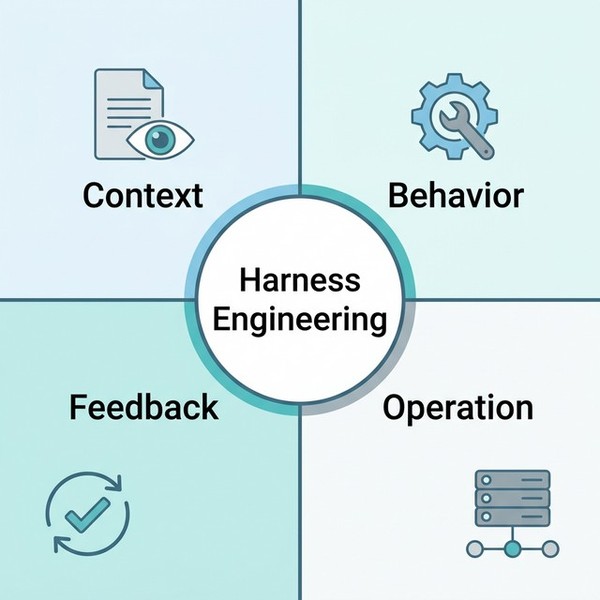
実務では、この環境設計を次の4つに分けて考えると整理しやすくなります。
- コンテキスト設計 : AIに何を見せるか
- 行動設計 : AIに何をさせ、どこまで許すか
- フィードバック設計 : AIの出力をどう評価し、どう修正させるか
- 運用設計 : セッションをまたいでどう回し続けるか
コンテキスト設計|AIに何を見せるか
コンテキストとは、AIが判断材料として受け取る情報全体のことです。プロンプト、ルールファイル、ソースコード、ログ、MCP経由の情報などが含まれます。
重要なのは、「たくさん渡すこと」ではなく「必要なものだけを、わかる形で渡すこと」です。情報を丸ごと投げると、AIはかえって迷います。
コンテキストは2種類に分類されます。
- 静的コンテキスト : AGENTS.md、設計ドキュメント、スタイルガイドなど。あらかじめリポジトリに置いておく、変わらない情報
- 動的コンテキスト : ログ・監視データ、ディレクトリ構造、CI/CDの実行結果など。実行のたびに変わる情報
設計の勘所は次の4つです。
- 書き出し : 状態や進捗を外部ファイルに記録する。エージェントの記憶(コンテキストウィンドウ)には限りがあるので、忘れても読み返せるようにしておく。TODO.mdやMEMORY.mdなど
- 選択 : タスクに必要な情報だけを渡し、不要な情報は見せない
- 圧縮 : 長い情報を要約して短くし、コンテキストウィンドウを節約する
- 分離 : サブエージェントに別のコンテキストウィンドウを割り当て、関係ない情報が混ざるのを防ぐ
要するに、コンテキスト設計はAIに「何を見せるか」を整える仕事です。
行動設計|AIに何をさせ、どこまで許すか
行動設計は、AIに「何をさせるか」と「どこまで動いてよいか」を決める領域です。エージェントに自由を与えすぎると、コードは急速にカオスに向かいます。
ここで重要なのは、AIに渡すツールや権限、ガードレール、アーキテクチャ制約をセットで設計することです。たとえば「このディレクトリしか編集できない」「本番DBには触れない」といったルールを決めておきます。
制約は、口約束ではなく仕組みとして埋め込みます。
- 自動リンター(ESLint等): コーディング規約を機械的にチェックする。たとえば「変数名はcamelCaseで書く」「未使用のimportは削除する」といったルールを自動で検出・修正する
- LLMベースのレビュー : リンターでは見つけられない、より高度な問題を別のAIが検出する。たとえば「この関数は責務が多すぎるので分割すべき」「このエラーハンドリングは不十分」といった設計レベルの指摘を行う
- 自動チェックのトリガー : コミット前やPUSHなどのトリガーでに自動で走るチェック。リンターやテストを自動実行する仕組み。
制約はAIを縛るためではなく、正しい道に乗せるためにあります。選択肢が整理されるほど、エージェントは迷走しにくくなります。
フィードバック設計|AIの出力をどう評価し修正するか
AIエージェントは、一発で完璧な答えを出す前提で使うより、出力を評価して軌道修正させる前提で設計したほうが安定します。ここが、単なるプロンプト設計とハーネス設計の大きな違いです。
評価手段はいくつもあります。もっとも基本なのはテストですが、それだけでは足りません。リンター、型チェック、E2Eテスト、レビュー用エージェント、監視ログなどを組み合わせて、「何がダメだったのか」をAIが読み取れる形で返す必要があります。
たとえば次のようなループです。
- 実装する
- テストやリンターを実行する
- 失敗理由をAIに返す
- AIが修正する
- 合格するまで繰り返す
この領域では、評価そのものよりも「失敗を次の行動につながる信号に変えること」が重要です。AIを監督する別エージェントや、ループ検知、完了前チェックリストなどもここに含まれます。
運用設計|セッションをまたいでどう回し続けるか
運用設計は、セッションをまたいでもエージェント開発を継続できるようにする領域です。1回の会話で終わる小タスクなら問題ありませんが、実務の開発は何日も続きます。
そのためには、記憶を外に出し、進捗を管理し、コードの劣化を定期的に掃除する仕組みが必要です。
- 進捗や判断を外部ファイルに残す。次のセッションのエージェントが途中から再開できるようにする
- 要件を小さな単位に分解する。1セッション1機能のように、AIが扱える粒度にする
- 実装とドキュメントのズレを検出する。READMEや設計書が実装からずれていないか確認する
- 小さな修正PRを自動で作成する。人間が短時間でレビューできるサイズに保つ
部屋と同じで、「散らかったら片づける」では追いつきません。AI時代のコードでは、運用そのものを設計し、継続的に回すことが前提になります。
ハーネスの導入は3段階で進める
ここまでで、ハーネスの全体像は見えたと思います。次に知りたいのは、「実際には何から作り始めればよいのか」です。
重要なのは、最初から巨大な仕組みを作らないことです。実務では、次の3段階で階段を登るように進めると失敗しにくくなります。
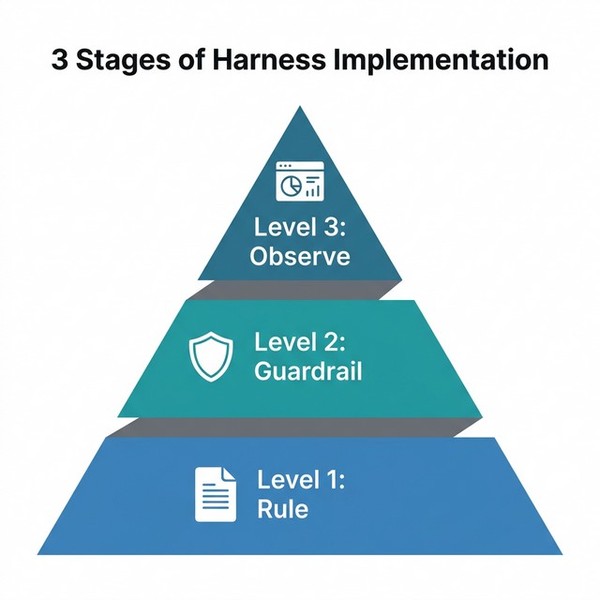
レベル1:ルールを明文化する
最初の一歩は、AIが迷わないための地図を作ることです。ここで効くのがCLAUDE.mdやAGENTS.mdのようなAI向け指示書です。
書くべき内容は、難しいことではありません。
- このリポジトリは何をするものか
- どこを触ってよく、どこは触ってはいけないか
- 仕様書や設計書はどこにあるか
- 標準的なビルド・テスト・コミット手順は何か
- このプロジェクトで守るべき命名規則や実装パターンは何か
たとえばAGENTS.mdなら、最小構成は以下で十分です。
- Build & Test : 正しい起動・テスト・lintコマンド
- Architecture Overview : 主要ディレクトリと依存の方向
- Security : 秘密情報や認証まわりのルール
- Git Workflows : ブランチ、コミット、レビューの流れ
- Conventions & Patterns : 命名規則、配置ルール、禁止事項
ポイントは、百科事典を書かないことです。入口になる短いファイルを置き、詳細は別ドキュメントへ案内します。AGENTS.mdは、仕様書そのものというより「何をどこで読めばいいか」を教える地図として設計したほうがうまくいきます。
また、AGENTS.mdは一度書いて終わりではありません。エージェントが同じ失敗をしたら、その失敗を二度と繰り返さないように1行ずつルールを追加して育てていくのが実践的です。
レベル2:制約と検証を仕組みに埋め込む
次にやることは、人間のレビューに頼らず、システム側でミスを防ぐことです。ここで初めてハーネスが「ガイド」から「ガードレール」に変わります。
具体的には、次のような制約と検証を自動化します。
- リンターや型チェック : コーディング規約違反を機械的に止める
- 自動テスト : 期待される動作を合否で返す
- アーキテクチャ制約 : 依存方向や禁止 import をチェックする
- レビュー用エージェントやジャッジ : 人間が見る前に怪しい変更をふるいにかける
- コミット前・PR前のフック : チェックが通らない変更を先に止める
この段階で大事なのは、「実装して終わり」ではなく「実装 -> 検証 -> 修正」のループを作ることです。
- AIが実装する
- テストやリンターが失敗を返す
- 失敗理由をAIが読む
- AIが修正する
- 通るまで繰り返す
さらに、安全性のガードレールもこの段階で入れます。たとえば、本番環境への直接アクセス禁止、最小権限、危険コマンドの制限、実行ログの保存、高速ロールバックなどです。良いハーネスは、AIを自由にさせる前に「どこまでは自律、どこからは停止か」を決めています。
レベル3:観測し、継続的に改善する
3段階目は、ハーネスを運用しながら改善する段階です。ここまで来ると、もはや指示書やルールの話だけではなく、実行ログと評価指標を使ってハーネス自体を育てていくフェーズに入ります。
見るべき指標は次のようなものです。
- スループット : タスク完了数、PR作成までの時間、マージまでの時間
- 品質 : CI通過率、本番バグ率、ロールバック頻度
- 人間の負荷 : レビュー時間、人間の介入回数
- 安全性 : ブロックした危険操作数、秘密情報検出数
- ハーネス健全性 : ドキュメントと実装の乖離、ルール違反の増減
実務では、セッションをまたぐ運用設計もここに入ります。AIは会話をまたぐと記憶を失うので、進捗や判断は外部ファイルに残し、1セッション1機能のように小さく区切り、次の実行で続きを再開できるようにします。
この段階で初めて、ログ、トレース、観測ダッシュボード、カスタムツール、マルチエージェント連携の投資が効いてきます。いきなりここから始めるのではなく、レベル1と2を整えたうえで入るのが順番です。
実務のワークフローの組み方
Explore → Plan → Implement → Verify → Record
3段階の土台ができたら、次は日々の開発フローに落とし込みます。おすすめは、エージェントにいきなり「作って」と投げるのではなく、次の順で動かすことです。
- Explore : 関連コード、仕様、ディレクトリ構造を読む
- Plan : 何をどう変えるかを小さな作業単位に分ける
- Implement : 1タスクずつ実装する
- Verify : テスト、lint、レビューで検証する
- Record : 進捗と判断を記録し、次回に引き継ぐ
この流れにしておくと、エージェントは場当たり的にコードを書き散らしにくくなります。
また、セッションをまたぐ場合は、1回で全部やらせないことも大切です。要件を小さく分割し、1セッション1機能、1PR1目的の粒度に落とすと、精度も再現性も大きく上がります。
ハーネス設計の3原則
軽量に始める
AIの世界は変化が速いので、最初から壮大な仕組みを作るとすぐ陳腐化します。まずは薄く始めて、必要なものだけを足していく設計のほうが強いです。
失敗を前提に多層防御する
1つのガードが破られても、次の層で止める設計にします。ルールファイル、権限制御、リンター、テスト、レビューエージェント、人間承認は、どれか1つで完全に守るものではなく、重ねて効かせるものです。
人間を最後の承認者に残す
自律性を高めても、人間を完全に外すべきではありません。とくに本番変更、権限操作、顧客影響の大きい差分は、人間が最終承認する前提で設計したほうが安全です。
ハーネスエンジニアリングで避けるべき5つのミス
ハーネスエンジニアリングでよくある失敗も整理しておきます。
- 作り込みすぎる : 最初から複雑にしすぎると、モデルや運用が変わった瞬間に壊れる
- ルールを書いて終わる : 実行結果を見ずに放置すると、ハーネスはすぐ陳腐化する
- 曖昧な指示に頼る : 「いい感じにやって」は再現性が低い。禁止事項や期待結果は具体的に書く
- 検証を人間に押しつける : テストやリンターで返せるものまで人間レビューに回すと、すぐに詰まる
- 暗黙知を放置する : チームメンバーの頭の中にしかない知識は、エージェントにとって存在しない
まとめ|まずは既存のハーネスを触ってみよう
ここまで読んでも、まだハーネスが完全には腑に落ちていない人は多いと思います。それは自然なことです。
たとえば、プログラミングを学び始めた頃に「オブジェクト指向」や「フレームワーク」という言葉を聞いても、座学だけではなんとなくわかったようで、実感は持ちにくかったはずです。けれど実務で実際に触ってみると、「こういうことだったのか」と一気に解像度が上がります。
ハーネスも同じです。定義や分類を読むだけで完全に理解するのは難しく、実際に動いているものを触って初めて、「どこまでがモデルで、どこからがハーネスなのか」「なぜツールやガードレールやフィードバック設計が重要なのか」が見えてきます。
なので、おすすめは、自分でゼロから作り始める前に、まずはOpenClawのような既存のハーネスを一度触ってみることです。実際に動かし、ログを見て、どんなルールが入り、どう評価され、どう修正ループが回っているかを観察すると、理解のスピードが大きく変わります。
ハーネスエンジニアリングは、読むだけで身につく知識というより、触って初めて腹落ちする実践知です。まずは他の人が作ったハーネスを体験し、そのうえで自分たちの開発現場に合う形へ作り変えていくのが、最も現実的な入り方だと思います。
