ハーネスとは、AIエージェントを実装するための設計や仕組みのことです。より一般的に使われる表現は「scaffolding(スキャフォールディング)」や「orchestration framework」です。
オーケストレーション、サブエージェント、エージェントスキルなどは、ハーネスを設計・実装する際の構成要素にあたります。この記事では、ハーネスの定義と構成レイヤー、そして設計のベストプラクティスまでを体系的に解説します。
AIエージェントのハーネスとは
ハーネスの定義と役割
AIエージェントのハーネスとは、AIモデルの周囲を取り囲む運用ソフトウェア層です。Salesforceの定義によれば、「AIモデルのライフサイクル、コンテキスト、および外部世界との相互作用を管理するソフトウェアインフラストラクチャ」とされています。
具体的にハーネスが担う役割は次のとおりです。
- ツール管理: モデルが外部APIやファイルシステムに安全にアクセスする仕組みを提供する
- コンテキスト管理: 長時間のタスクでも重要な情報を失わないよう、文脈を圧縮・整理する
- 状態管理: エラーやシステム再起動が起きても、作業の進捗を保存・復元する
- 安全制御: 不可逆な操作の前に人間の承認を求める仕組みを設ける
つまり、AIエージェントにおいてモデルは「何を・なぜやるか」を決め、ハーネスは「どうやって・どこでやるか」を制御するのです。
類義語との関係|スキャフォールディング・オーケストレーションとの違い
ハーネスと似た意味で使われる用語に「スキャフォールディング」と「オーケストレーション」があります。これらは重なる部分もありますが、それぞれ焦点が異なります。
| 用語 | 焦点 |
|---|---|
| ハーネス | モデルを包む実行基盤全体(ツール管理・コンテキスト管理・状態管理・安全制御を含む) |
| スキャフォールディング | モデルの能力を拡張する構造的な足場(RAG、プロンプト最適化など) |
| オーケストレーション | 複数エージェントの制御フローと協調(ルーティング、並列処理など) |
スキャフォールディングは、もともとプロンプト最適化やRAG(検索拡張生成)など、モデルの推論能力を補強する構造を指す用語でした。エージェントの文脈では、プランナー・メモリ・ツール統合を含むより広い設計を指すこともあります。
実務では、これらの用語は厳密に区別されないことも多いです。ただし、ハーネスが最も包括的な概念であり、オーケストレーションやスキャフォールディングはハーネスを構成する一部の要素と捉えると理解しやすくなります。
「モデル」と「ハーネス」の関係
モデルは言語理解と推論の能力を持っています。しかし、モデル単体では「ファイルを読む」「APIを叩く」「進捗を記録する」といった現実の操作はできません。ハーネスがモデルの入出力を橋渡しし、外部ツールとの接続やエラー復旧を担うことで、初めてエージェントとして機能します。
Anthropicのエンジニアリングブログでは、長時間稼働エージェント向けのハーネス設計が紹介されています。初期化エージェントとコーディングエージェントの2つを連携させるアーキテクチャです。このように、ハーネス設計のパターンがエージェントの実用性を大きく左右します。
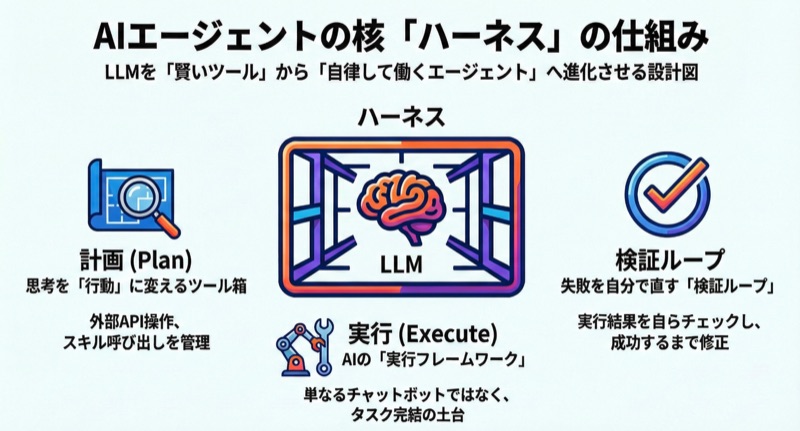
ハーネスを構成する4つのレイヤー
ハーネスの設計パターンはプロダクトや用途によってさまざまですが、ここでは役割ごとに4つのレイヤーに分けて整理します。あくまで代表的なパターンの一つとして捉えてください。
その前に、よくある疑問に答えておきます。「ハーネスってプログラムのコードなの? それとも自然言語のプロンプトなの?」という点です。
答えは「基本的にはコード(プログラム)」です。ハーネスは、PythonやTypeScriptなどで書かれたソフトウェアとして、AIモデルの外側に存在します。モデルにどんな情報を渡すか、ツールの実行結果をどう処理するか、エラー時にどう再試行するか――こうしたロジックをプログラムとして実装したものがハーネスです。
ただし、自分でコードを書かなくてもハーネスを使うことはできます。Claude CodeやCursorのような製品は、ハーネスがすでに組み込まれた完成品です。ユーザーは自然言語で指示を出すだけで、裏側のハーネスが自動的にツール管理・コンテキスト管理・検証を行ってくれます。一方、LangGraphやCrewAIなどのフレームワークを使って自分でエージェントを構築する場合は、ハーネスのコードを自分で書くことになります。
この記事で出てくるPythonのコード例は、各レイヤーが「内部で何をしているか」をわかりやすく示すための概念図です。実際のプロダクトのコードそのものではありません。
もちろん、すべてのAIエージェントがこの4層構造を採用しているわけではありません。Salesforceは「コンテキスト管理・ツール調整・人間主導型コントロール・状態管理」の4構成要素を、Microsoftは「ルーティング・並列処理・司令塔と作業員」の3パターンを提唱しています。ここではこれらを横断的に整理し、制御・実行・検証・コンテキストの4レイヤーとしてハーネスの全体像を捉えます。
制御レイヤー(Control Plane)
要素: エージェント オーケストレーション、サブエージェントのルーティング、状態管理
制御レイヤーは、ハーネス全体の「交通整理役」です。ユーザーのリクエストを受け取り、タスクを分解し、どのモデルやサブエージェントに何を振るかを決定します。
例えば「このプロジェクトにログイン機能を追加して」というリクエストが来たとします。制御レイヤーは、このタスクを「UIの作成」「認証ロジックの実装」「テストの追加」などに分解し、それぞれ適切なエージェントへ振り分けます。MicrosoftのAIエージェント設計パターンでは、この振り分け方として「ルーティング(1つずつ最適な担当へ回す)」「並列処理(複数のエージェントに同時に投げる)」「司令塔と作業員(マネージャーが計画を立て、作業者に指示を出す)」の3パターンが紹介されています。
コードで見ると、制御レイヤーの中核はこのようなルーティング処理です。
class ControlPlane:
def __init__(self):
self.agents = {
"code": CodingAgent(),
"test": TestingAgent(),
"review": ReviewAgent(),
}
self.state = TaskState()
def route(self, task: Task) -> Agent:
"""タスクの種類に応じて適切なエージェントを選択する"""
if task.requires_code_change:
return self.agents["code"]
if task.requires_testing:
return self.agents["test"]
return self.agents["review"]
def execute(self, request: str):
subtasks = self.decompose(request)
for task in subtasks:
agent = self.route(task)
result = agent.run(task, context=self.state)
self.state.update(task, result)制御レイヤーが賢いほど、エージェント全体の効率は上がります。逆に、ルーティングが雑だと、専門外のエージェントに作業が回り、無駄なトークン消費やエラーの原因になります。
実行レイヤー(Execution Plane)
要素: エージェントスキル(ツール/関数)、外部API連携、サンドボックス環境
実行レイヤーは、モデルの「思考」を「行動」に変換する道具箱です。制御レイヤーが「何をやるか」を決めたあと、実際にファイルを読み書きしたり、APIを叩いたり、コマンドを実行したりするのがこのレイヤーの役割になります。
重要なのは、単にツールを呼び出すだけではない点です。Salesforceの解説によれば、ハーネスの実行レイヤーには5段階のプロセスがあります。モデルがツールを使う「意図」を検出し、権限を検証し、隔離環境で実行し、出力をサニタイズ(整形・無害化)してからモデルに返すという流れです。
class ExecutionLayer:
def call_tool(self, tool_name: str, params: dict) -> ToolResult:
# 1. 権限チェック
if not self.is_permitted(tool_name, params):
return ToolResult(error="権限がありません")
# 2. サンドボックス内で実行
sandbox = Sandbox(timeout=30, memory_limit="512MB")
raw_result = sandbox.execute(tool_name, params)
# 3. 出力をモデルが理解しやすい形に整形
formatted = self.format_for_model(raw_result)
return ToolResult(output=formatted)
def format_for_model(self, raw_output: str) -> str:
"""長大な出力を要約し、重要部分だけ抽出する"""
if len(raw_output) > 5000:
return self.summarize(raw_output)
return raw_outputたとえば、エージェントがコマンドを実行してエラーが出た場合を考えてみてください。生のスタックトレースは数百行に及ぶこともあります。実行レイヤーはこれを「エラーの種類」「発生箇所」「推定原因」に整形してからモデルに渡します。モデルが次の判断を下しやすいように出力を加工する点が、単なるAPI呼び出しとの決定的な違いです。
検証・修復レイヤー(Verification & Feedback)
要素: 自己検証ループ、ユニットテスト、静的解析、フィードバック機構
検証・修復レイヤーは、ハーネス設計の中で最もエージェントの成功率を左右する要です。AIの出力が「仕様通りか」「コンパイルが通るか」「テストをパスするか」を自動チェックし、失敗時にはフィードバックを添えて再試行を促します。
なぜこのレイヤーがそこまで重要なのか。AIモデルは確率的に出力を生成するため、一発で完璧な回答を出すことは稀です。しかし「何がダメだったか」という情報があれば、高い確率で修正できます。検証・修復レイヤーは、この「失敗から学ぶサイクル」を自動化する仕組みです。
Anthropicのハーネス設計では、機能ごとにテスト項目をJSON形式で定義し、エージェントがブラウザ自動操作ツール(Puppeteer)で実際の動作を検証する仕組みが紹介されています。テスト項目の削除や改変を禁止する厳格なルールを設けることで、エージェントが「テストをごまかす」ことを防いでいます。
class VerificationLayer:
def verify_and_fix(self, code: str, max_retries: int = 3) -> str:
for attempt in range(max_retries):
# 静的解析でコード品質をチェック
lint_result = self.run_linter(code)
if lint_result.errors:
code = self.request_fix(code, lint_result.errors)
continue
# ユニットテストを実行
test_result = self.run_tests(code)
if test_result.failed:
# 「何が失敗したか」をフィードバックとして渡す
feedback = self.build_feedback(test_result)
code = self.request_fix(code, feedback)
continue
return code # すべてのチェックを通過
raise MaxRetriesExceeded("検証ループの上限に達しました")このサイクルは「Maker-Checkerパターン」とも呼ばれます。MicrosoftのAIエージェント設計パターンでは、あるエージェントが出力を「作り」、別のエージェントがそれを「検査」し、不合格なら差し戻す――というループが品質管理の基本形として紹介されています。検証レイヤーがないエージェントは、間違った出力をそのまま返す「ぶっつけ本番」の状態です。
自己検証=モデルの「学習」ではない
ここで誤解されやすいポイントを整理します。ハーネスの自己検証は、モデルの重みを書き換える「ファインチューニング(学習)」ではありません。プロンプトを事前に手直しする作業とも異なります。
自己検証とは、「推論→実行→失敗→修正」というサイクルをコード(ハーネス)側で自動化する仕組みです。モデルの重みを更新するには数千件のデータと多大なコストが必要ですが、ハーネスの検証は違います。「コンパイルが通らなかった。エラーログはこれ。もう一回考えて」と、1回のタスクの中でモデルに即座にフィードバックを返すだけです。
プロンプトの修正とも違う点があります。事前にプロンプトを完璧にするのではなく、「失敗したという事実とその原因(ログ)」を次の推論のコンテキストに動的に追加するのです。つまり、自己検証の本質は「対話的なデバッグ」であり、モデルの中身を変えずにハーネスの仕組みだけでエージェントの出力品質を高めるアプローチになります。
コンテキストレイヤー(Contextual Awareness)
要素: RAG(検索拡張生成)、長期メモリ、トレース(実行ログの追跡)
コンテキストレイヤーは、エージェントが「今、何をすべきか」を正しく判断するための文脈を提供する層です。過去の試行錯誤、プロジェクトの仕様、環境情報を適切にフィルタリングし、モデルのコンテキストウィンドウに収まる形で注入します。
このレイヤーがないと何が起きるか。前のセクションで触れた「コンテキストの腐敗」が発生します。長時間のタスクでは情報が蓄積される一方です。すべてをコンテキストに詰め込むとモデルは混乱し、古い情報に引きずられた判断をしてしまいます。
Anthropicのハーネス設計は、コンテキストレイヤーの実例として参考になります。claude-progress.txtというファイルにセッションごとの作業記録を残し、git履歴と組み合わせることで、新しいセッションが過去の文脈を即座に把握できる仕組みです。
class ContextLayer:
def build_context(self, current_task: str) -> str:
"""モデルに渡す文脈情報を組み立てる"""
context_parts = []
# 1. 進捗ファイルから直近の作業状況を取得
progress = self.read_progress_file("claude-progress.txt")
context_parts.append(f"## 直近の進捗\n{progress}")
# 2. RAGで現在のタスクに関連する情報を検索
relevant_docs = self.rag_search(current_task, top_k=5)
context_parts.append(f"## 関連ドキュメント\n{relevant_docs}")
# 3. 直近のgitログから変更履歴を取得
git_log = self.get_recent_commits(limit=10)
context_parts.append(f"## 直近の変更履歴\n{git_log}")
return "\n\n".join(context_parts)コンテキストレイヤーの設計で肝になるのは「何を渡すか」より「何を渡さないか」です。モデルに渡す情報は少ないほど判断の精度が上がります。Weaviateはこれを「コンテキストエンジニアリング」と呼び、必要な情報だけを選別してモデルに届ける技術こそがエージェントの性能を決めると指摘しています。
各レイヤーの連携と全体像
これらのレイヤーは独立して存在するのではなく、1つのループとして連動します。リクエストが入ってから結果が返るまでの流れを整理すると、次のようになります。
- 制御レイヤーがリクエストを受け取り、タスクを分解・ルーティングする
- コンテキストレイヤーが、担当エージェントに必要な文脈情報を注入する
- 実行レイヤーが、ツールやAPIを使って実際の作業を行う
- 検証・修復レイヤーが、出力の品質をチェックする
- 不合格なら、フィードバックを添えて手順2に戻り再試行する
- 合格なら、制御レイヤーが次のタスクに進むか、最終結果を返す
このサイクルは、人間の開発者の作業フローとよく似ています。仕様を確認し(コンテキスト)、作業計画を立て(制御)、コードを書き(実行)、テストを回して不具合を修正する(検証・修復)。AIエージェントのハーネスは、この自然なワークフローをソフトウェアとして再現した構造と言えます。
ここまで各レイヤーを理論的に解説してきました。次のセクションでは、これらのレイヤーが実際のプロダクトでどのように実装されているか、具体的なハーネスの事例を見ていきます。
ハーネスの具体例
各レイヤーの理論を踏まえたところで、実際のプロダクトではハーネスがどう実装されているのかを具体例で見ていきます。
SNS投稿エージェントで見るレイヤーの連携
コーディング以外の例も見てみましょう。たとえば、Xに自動投稿するAIエージェントを4レイヤーで設計するとどうなるか。このケースでは、ハーネスが「投稿→分析→改善」のPDCAサイクルを自律的に回す構造になります。
制御レイヤー(戦略立案)
「今はエンジニア界隈で『ハーネス』が話題になっているから、その解説ポストを作ろう」と投稿戦略を立てる役割です。トレンド分析エージェントやコンサルティングエージェントがここに位置します。
実行レイヤー(執筆・投稿)
戦略に基づいて実際にポストのドラフトを書き、X APIで投稿する層です。執筆エージェントが担当します。
検証・修復レイヤー(投稿前チェック)
投稿前に「利用規約に触れていないか」「文字数を超えていないか」「不快な表現がないか」を別のエージェントやプログラムで自動検証します。ここは「事前の品質ゲート」です。
コンテキストレイヤー(PDCAの心臓部)
ここが最も重要な層です。投稿から24時間後、ハーネスがAPI経由でインプレッション数やエンゲージメント率を取得します。「昨日の投稿は伸びなかった。原因は専門用語が多すぎた」といった分析結果を長期メモリに保存し、次回の執筆時に「前回の失敗を考慮して書け」とプロンプトに動的に注入します。
このサイクルのポイントは、モデルを再学習させなくても「仕組み(ハーネス)が経験を積む」ことでエージェント全体のパフォーマンスが向上する点です。AIエージェントの最大の弱点は「やりっぱなし(ステートレス)」であることですが、外部APIとの連携(数値を取得する「手足」)、評価ロジック(「100いいね以下は改善対象」と定義する判断基準)、メモリ管理(失敗を忘れないための記憶装置)をハーネスとして実装することで、自律的に改善し続けるシステムになります。
ハーネス設計のベストプラクティス
具体例を見てきたところで、自分でAIエージェントのハーネスを設計・構築する際に共通して押さえるべきポイントを整理します。
コンテキスト管理を軽視しない
「コンテキストの圧迫」こそがAIエージェント開発における最大のボトルネックであり、それを解決する技術が「コンテキストエンジニアリング」の本質です。PDCAを回すほどログが溜まり、推論の質が下がる(またはコストが爆増する)。この課題に対して、Anthropic・OpenAI・Martin Fowlerらが提唱する4つの戦略を組み合わせるのが現在のベストプラクティスです。
戦略1: 圧縮と要約
履歴をそのまま保持せず、一定のしきい値(コンテキストウィンドウの80〜90%など)を超えたら過去の経緯を要約して入れ替えます。冗長な情報(生のエラーログや巨大なコード)をパス名や短いステータスコードに置き換える「コンパクション」や、LLM自身に過去のやり取りを「教訓と現在のステータス」だけに凝縮させる「再帰的要約」が代表的な手法です。
戦略2: 外部アーティファクト化
チャット履歴に頼らず、「現在の結論」を外部ファイルやDBに書き出す手法です。Anthropicが推奨するprogress.txtパターンでは、エージェントが毎ステップ終了時に「現在の進捗」と「次にやるべきこと」をファイルに上書き保存します。次回起動時は過去の全ログではなく最新のprogress.txtだけを読み込めば済むため、コンテキストを劇的に節約できます。
戦略3: 階層型メモリ
OSの「RAM」と「ストレージ」の関係のように、メモリを階層化する手法です。今まさに処理しているタスクのログを「短期メモリ」に、過去のPDCAから得られた汎用的な教訓だけを「長期メモリ」に保存します。たとえばSNS投稿エージェントなら、「昨日の投稿ログ」そのものは捨て、そこから得られた「夜20時のIT系投稿は伸びやすい」というルール(教訓)だけをベクターDBに保存し、必要なときだけ呼び出す設計です。
戦略4: 動的コンテキスト注入
全履歴をプロンプトに入れるのではなく、今のタスクに関係しそうな過去ログだけをRAG(検索)で引っ張ってきて注入する手法です。OpenAIのハーネスエンジニアリングでは「地図を渡せ、1000ページのマニュアルは渡すな」と表現されています。渡す情報は「今のタスクに必要な最小限」に絞り、詳細は参照先のポインタだけを添えるのが効果的です。
これらの戦略は排他的ではなく、組み合わせて使います。生データを持ち続けるのは下策であり、「なぜ成功/失敗したかの分析(言語化)」を行い、その教訓だけを長期メモリに保存するのが最もスマートな設計です。
コンテキストエンジニアリングの参考リソース
コンテキスト管理の設計を深く学びたい方は、以下のリソースが参考になります。
- Anthropic: Effective harnesses for long-running agents ─ 長いタスクを複数のコンテキストウィンドウに跨がせる手法と
progress.txtパターンの解説 - Martin Fowler: Context Engineering for Coding Agents ─ 「コンテキストは一気に流し込むのではなく、徐々に構築すべき」という設計思想
- OpenAI: Harness engineering ─ Codexを用いたハーネスだけでシステムを改善し続ける手法
- LangChain Blog: Context Engineering ─ 「Write, Select, Compress, Isolate」の4戦略をコードベースで解説
コンテキスト管理は、ハーネスの中で最も地味な部分です。しかし、長時間稼働するエージェントの成功率は、この設計の質で決まると言っても過言ではありません。
まとめ|AIエージェントの品質はハーネスで決まる
ハーネスとは、AIエージェントを実装するための設計や仕組みです。どれほど高性能なモデルでも、ハーネスなしでは実用的なエージェントにはなりません。
この記事で解説したポイントを振り返ります。
- ハーネスの本質: AIエージェントを実装するための設計や仕組み。scaffolding(スキャフォールディング)やorchestration frameworkとも呼ばれ、モデルの入出力を橋渡しして現実の操作を可能にする
- 構成レイヤー: 制御・実行・検証・コンテキストなど、役割ごとにレイヤーを分けて設計すると整理しやすい。ただし、これは一つの設計パターンであり、プロダクトや用途に応じて構成は変わる
- 具体的な実装: SNS投稿エージェントのようなユースケースでも、同じレイヤー構造で「投稿→分析→改善」のPDCAサイクルを自律的に回せる
- 設計の鉄則: コンテキスト管理を軽視しないこと。生データを持ち続けるのではなく、教訓だけを長期メモリに保存する設計が鍵になる
AIエージェントの品質は、モデルの性能だけでは決まりません。ハーネスの設計こそが、エージェントの信頼性と実用性を左右する最大の要因です。まずは最小構成のハーネスから始めて、実際の運用から学びながら段階的に育てていくのが確実なアプローチです。

せお丸(田中淳介)
- 著書:「ITエンジニアのためのAI駆動開発入門」

- テック系Youtuber「せお丸」として活動(チャンネル登録者6万人)
- システム開発会社 代表取締役
- エンジニア歴20年以上